经手的实验平台多了以后从不同公司流量框架的设计和应用中吸取一些经验,下面展开说下我的理解
流量的理解
AB实验需要通过对随机、同质、独立的流量施加不同的方案,通过实验观测看不同方案的优劣。所以第一步是对自己流量的理解
- 流量的生态包括哪些参与者,比如
- 互联网中搜索引擎用户
- 电商领域中买家、卖家
- 内容领域中的消费者和创作者
- 外卖中骑手、商家、买家
- 游戏领域中玩家(又有玩法的区分比如PvP中玩家相互就不独立)
- 流量的随机性通常在流量框架中通过技术手段可以解决,比如hash分流、轮询分流等
- 流量的同质性正常在流量随机的过程中可以保障,在用户分布(画像、指标的分布)相对比较极端的场景需要进行同质性检验确保实验可信
- 流量的独立性在选择流量框架的时候需要重点考量,针对外卖、打车等场景简单随机无法保证流量的同质性和独立性,需要更复杂的流量框架或者分流算法
流量框架的选择
AB实验方法由Google引入互联网后,实验方法成为各大公司标配。实验的本质对随机打散的同质、独立流量施加控制。按照流量生态的差异大概沉淀出以下的流量框架
- 重叠流量框架,基于层域进行流量管理,被大多数互联网公司采样,可以参考Google论文 Overlapping Experiment Infrastructure: more,better,faster experimentation 重叠实验框架:更多更好更快的做实验 ,在实验配置的时候进行参数的冲突检测。
- 基于约束的流量框架,通常适合双边、多边业务形态的公司。由实验者制定约束,平台根据实验者制定的约束,确保无法避免潜在交互影响的实验没有同时曝光给用户。如微软、Uber等公司,实验平台都集成了检测交互作用的自动化系统,以避免实验间潜在交互影响。
实践案例
市场上实验平台的设计都要在充分理解业务流量的基础上,解决流量分配随机、同质、独立要求,具体的实现路径就是重叠流量框架(在实验的时候再进行参数冲突控制)、基于约束的流量框架(本质是一种提前进行实验参数冲突控制的策略)
Google重叠流量框架以及四种实现
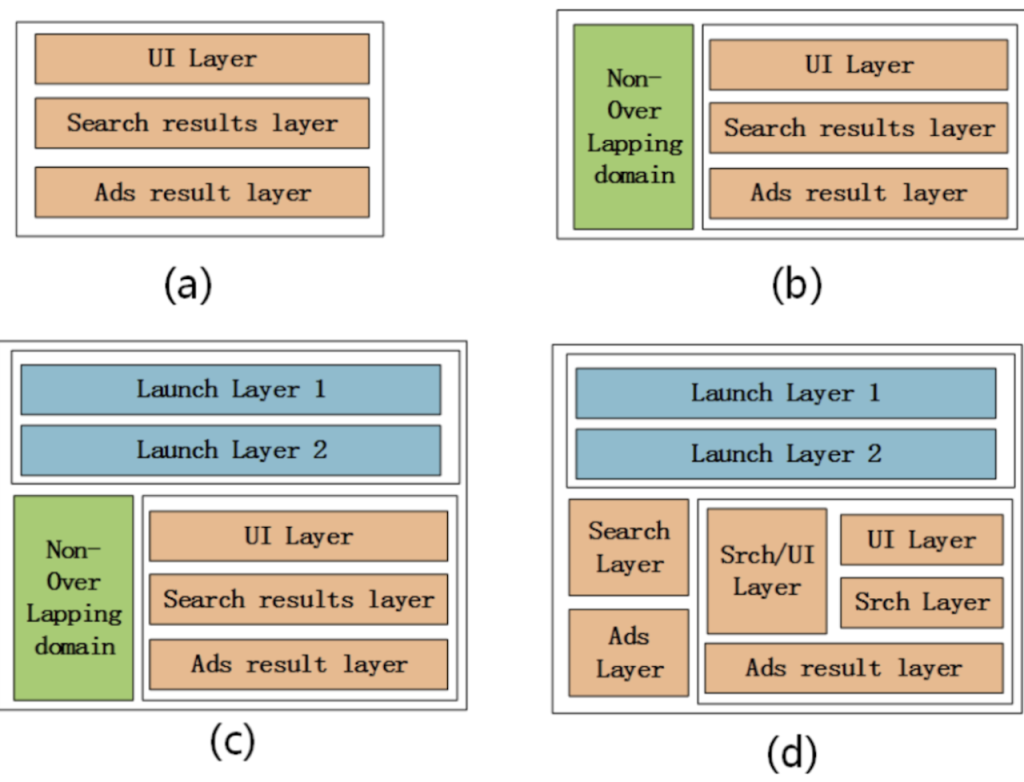
不同公司按照业务的复杂度,可以选择figure a-d四种不同复杂度的流量框架实现。
美团AB实验白皮书
白皮书 中介绍了美团流量的特点、流量框架的设计,以及提供的一系列实验分析工具,整体上确保实验平台的科学可信。
滴滴Adaptive分流
参考:https://blog.51cto.com/u_15060460/2673616
随机分流的过程中进行用户指标的平衡,增强流量的同质性
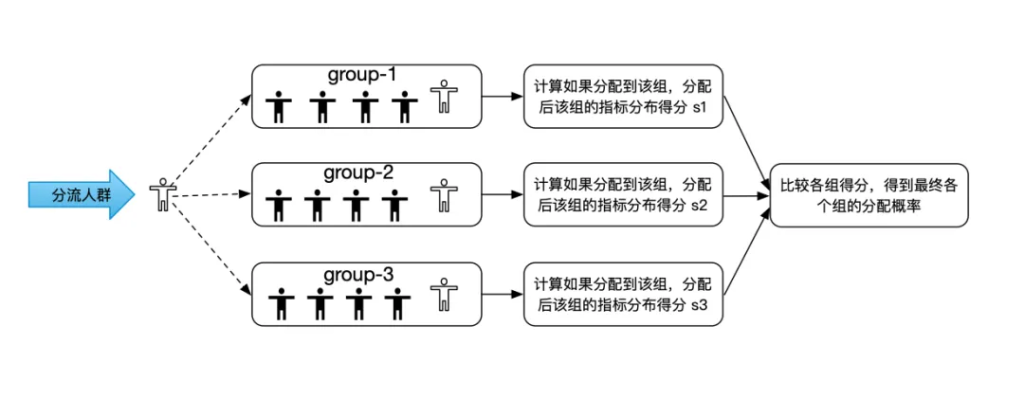
分流单元定义和分流方法
流量生态和流量框架的结合包括分流单元的定义和分流方法的选择。
分流单元
通常的分流单元可以包括以下:
- user_id 适用大部分互联网场景,包括device_id、cookie_id、uuid等类似标识
- request_id 适用商业化场景
- poi、Geohash等位置标识,适用O2O等场景
分流方法
- hash分流,随机分流并且分流结果固定,通常在重叠流量框架中通过层id等加盐确保层间正交性、时间戳更新进行流量再打散等
- 轮询方法,在用户属性(国家、设备等)或者先验指标(例如ecpm)方差较大情况下通过轮询方法保证各组流量的同质性,通过随机进行轮询顺序的打散,通过cache确保流量进组的稳定性
以上总结了实践中对流量生态理解、流量框架选择、以及具体流量框架实现中的一些考量。 关键要解决
- 流量的随机性、独立性、同质性
- 流量分配和参数控制中避免冲突
从而确保流量框架的可信性、实验结果的科学置信。