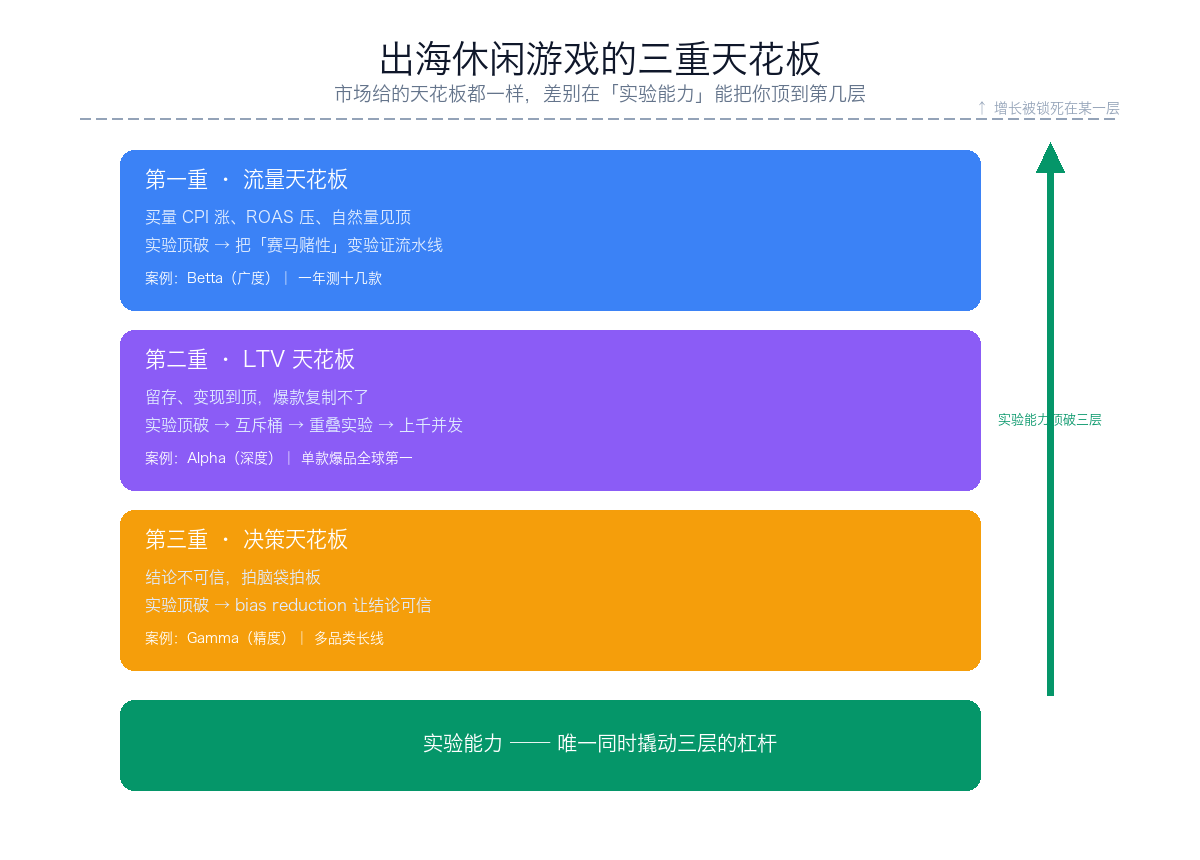
服务范围声明:本工作室聚焦 内容、电商、SaaS 与平台型业务 的实验与增长基础设施建设,不承接游戏(含手游 / 休闲 / 中重度)行业及相关出海投放业务。
把业务数据、实验能力和 AI Agent,变成可控的增长决策系统。
面向内容、电商、SaaS 与平台型业务,提供 实验体系建设、营销数据平台、决策工作流、企业级 Agent 共建 四类服务。
从统一数据与指标口径 → 实验与因果验证 → 业务洞察与决策工作流 → Agent 辅助与受控执行 → 效果追踪与规则迭代,形成同一条闭环能力链。
你是否正在面对这些问题?
| 你正在经历的现象 | 深层问题 | 可切入的服务 |
|---|---|---|
| 多个业务后台、数据源、BI 的数字对不上 | 指标与数据资产未统一 | 营销数据底座与指标治理 |
| 复盘高度依赖资深业务专家,经验难复制 | 决策逻辑没有产品化 | 决策工作流与策略沉淀 |
| 有实验工具,但实验量少、结果不被采用 | 实验机制未进入业务流程 | 实验平台与实验运营体系 |
| 团队在尝试 AI,却停留在聊天、报表和 Demo | 没有可靠的业务闭环 | Agent 场景设计与 PoC |
| 想做流程自动化,但担心系统乱改和不可追责 | 缺少权限、审计、回滚机制 | 受控执行与 Agent 治理设计 |
30 秒内如果发现"这就是我团队的问题",可以从 → 服务包 开始。
服务包:从诊断到共建,逐层承诺
| 服务包 | 适合场景 | 典型周期 | 核心交付物 |
|---|---|---|---|
| 增长智能化诊断 | 正在判断是否应建设数据、实验或 Agent 能力 | 2 – 3 周 | 现状评估、问题地图、优先级矩阵、建设路线图 |
| 关键场景 PoC | 已有明确痛点,需要验证价值 | 4 – 8 周 | 单场景闭环、数据与接口方案、评估指标、上线建议 |
| 平台共建与能力落地 | 多团队、多市场、长期增长基础设施升级 | 3 – 6 个月或分阶段 | 目标架构、系统方案、核心模块、治理机制、团队赋能 |
不预设固定报价,但每一层的合作形态是公开的——→ 服务详情与交付方式
差异化组合:实验科学 × 数据平台 × 企业级 Agent
我不是泛 AI 顾问,也不是单一业务工具外包。稀缺组合来自四条能力线的交叉:
- 实验科学:流量分层、因果验证、指标治理、统计分析引擎
- 营销数据平台:多源归因、指标语义层、ROI360、行为与内容数据模型
- 增长与营销科技方法论:漏斗诊断、渠道生命周期、批量运营、策略引擎
- 企业级 Agent 治理:Schema 居中、分级授权、可审计执行、独立验证与效果闭环
方法论已公开写在《企业级 Agent 建设实践》《极致 AB 实验的前置》等长文中——不是"会调用模型",而是"知道怎样让 AI 在企业约束下可靠运行"。
精选案例
- 增长数据三套口径、ROI 差 35% 的诊断与重建 — 中大型增长团队,从"三套数吵架"到"数据可信 + 归因清晰"。
- 增长平台从 L1 到 L4 的演进 — 从多后台人工操作,到统一数据底座、策略引擎、受控 Agent 执行。
- A/B 实验平台与实验文化建设 — 支持从个位数到百 / 千量级并发实验,创意 → 研发 → 实验 → 分析闭环。
- 策略产能:增长团队的第二增长曲线 — 把资深专家经验沉淀成规则引擎、信号和 playbook。
每个案例回答同一组问题:客户处于什么条件、原始问题是什么、方法与架构如何选、交付边界在哪、可公开的能力指标、能迁移到哪些团队。
这不是为了做一个 AI Demo
对增长团队而言,目标是:
- 减少 人工对账与盯盘时间;
- 提高 问题发现与决策响应速度;
- 让 有效策略可复用、可复跑;
- 在 明确权限边界内逐步实现受控执行。
每一个服务、每一份交付、每一个案例,都会回到四个问题:它替客户减少了什么成本?提升了什么决策质量或速度?降低了什么业务风险?如何证明它真的有效?